tomcat
web安全
网络安全
开源
单例模式
codeforces
笔试题
random
intellij-idea
QTextToSpeech
openssl
flume
业界资讯
区别
Smart Tomcat
图片提取
主备
数字IC
因果图
微信公众平台
网页爬虫
2024/4/12 13:05:06

关于Python爬虫使用技巧
首先,Python是一种非常流行的编程语言,拥有广泛的应用领域,例如数据分析、人工智能、Web开发等。如果您是初学者,可以开始学习基础的语法和概念,例如变量、数据类型、循环、函数等等。许多在线资源可以提供学习资料。 …


C++下载器程序:如何使用cpprestsdk库下载www.ebay.com图片
本文介绍了如何使用C语言和cpprestsdk库编写一个下载器程序,该程序可以从www.ebay.com网站上下载图片,并保存到本地文件夹中。为了避免被网站屏蔽,我们使用了亿牛云爬虫代理服务提供的代理IP地址,以及多线程技术提高下载效率。
首…

Jsoup 爬取页面的数据和 理解HTTP消息头
推荐一本书:黑客攻防技术宝典.Web实战篇 ; 顺便留下一个疑问:是否能通过jsoup大量并发访问web或者小型域名服务器,使其瘫痪?其实用jsoup熟悉的朋友可以用它解析url来干一件很无耻的事(源码保密)…

如何设计一个网页爬虫
作为长期深耕在爬虫行业的程序猿来说,对于设计一个网页爬虫想必很简单,下面就是一些有关网页爬虫设计的一些思路,可以过来看一看。
第一步:简述用例与约束条件
把所有需要的东西聚集在一起,审视问题。不停的提问&…


padans关于数据处理的杂谈
情况:业务数据基本字段会有如下:
Index([时间, 地区, 产品, 字段, 数值], dtypeobject)这样就会引发一个经典“三角不可能定理”,如何同时简约展现分时序、分产品、分字段数据。)一般来说,
1、时序为作为单独的分类&…
Python爬虫学习之-从零开始
大家好,相信点进来看的小伙伴都对爬虫非常感兴趣,博主也是一样的。博主刚开始接触爬虫的时候,就被深深吸引了,因为感觉SO COOL啊!每当敲完代码后看着一串串数据在屏幕上浮动,感觉很有成就感,有木…

使用 Python Selenium 提取动态生成下拉选项
在进行网络数据采集和数据分析时,处理动态生成的下拉菜单是一个常见的挑战。Selenium是一个强大的Python库,可以让你自动化浏览器操作,比如从动态生成的下拉菜单中选择选项。这是一个常见的网页爬虫和数据收集者面临的挑战,但是Se…
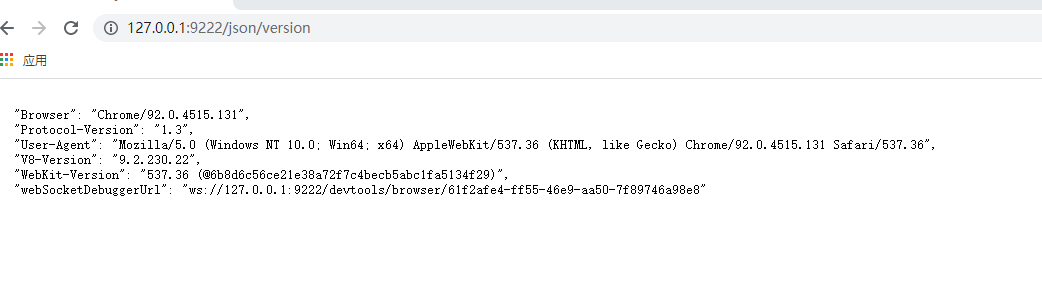
打开谷歌浏览器远程调试功能
谷歌浏览器远程调试功能
首先我们来启动Chrome的远程调试端口。你需要找到Chrome的安装位置,在Chrome的地址栏输入chrome://version就能找到Chrome的安装路径 开启远程控制命令
文件路径/chrome.exe --remote-debugging-port9222开启后的样子(注意要关闭其他谷歌浏…
